The rise of ChatGPT and BARD based on large language models (LLMs) has shown the potential of generative models to assist with a variety of tasks. However, we want to highlight how generative models can be used in many more areas than just language generation, with one particularly promising area: molecule generation for chemical product development.
Conventional discovery of new molecules is often done through expensive and time-consuming trial-and-error approaches. This means that scientists may miss many potential candidates. Instead, generative models can be used to explore molecular spaces and discover molecules that have not been synthesized in the lab or even theorized in simulations. These novel molecules could therefore be patented.
Generative Models: A New Method for Molecule Discovery
In the generative models, an important aspect is the molecules representation, with some of the more common representations being molecular graphs, SMILES, and SELFIES. SELFIES have the additional advantage that every SELFIE string is a valid molecule. This allows for SELFIES to be mutated or generated from latent space and still represent a valid molecule. These molecule representations are the input to the generative model, with some of the more popular generative models being variational autoencoders (VAEs), generative adversarial networks (GANs), and normalizing flow.
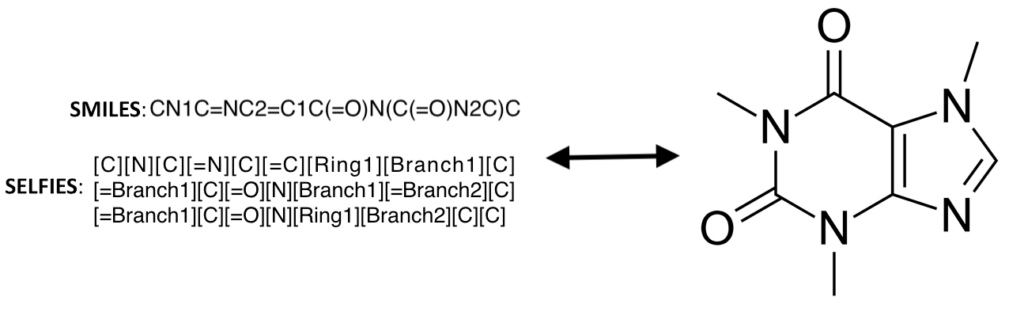
SELFIES, SMILES, and molecular graph representations of the caffeine molecule
These generative models are unsupervised models, which means they don’t require knowing the properties of the molecules (i.e. unlabeled). The models can therefore be trained on large databases of molecules even if they don’t have the properties of interest. For example, the models can be trained on large existing open-source molecule databases, such as ChEMBL or QM9, which significantly reduces the cost and complexity of data collection.
Challenges and Solutions for Generation Models
However, there are some problems with this approach. For example, the generated molecules might not satisfy all property requirements, might be difficult and costly to synthesize, or may not meet other business requirements like manufacturability. This can be especially difficult when there are multiple business requirements. Fortunately, there are several different solutions to this.
One option is to use a funnel or filter approach. In this approach, many molecules are generated and then each molecule is checked to see if it passes certain requirements. If it doesn’t pass the requirement, the molecule is removed from the potential molecules. Then the remaining molecules will be tested on the next filter until all filters have been tested. These filters can be a simulation, experiment, or even a machine learning (ML) model. While this approach is rather simple, there are some advantages to it. For one, cheaper filters can be used first to reduce the number of candidate molecules, reducing the overall cost of discovering a new molecule. The cheap filters are any test that can be done quickly and at a low cost for many molecules, such as a ML model or simulation. However, this approach can still be very expensive if the filters are expensive, with some lab experiments and simulations being costly and time-consuming to run.
In the case where there are no robust and cheap models, another approach is to guide the exploration of these novel regions of chemical space using methods such as Bayesian optimization or active learning. Bayesian optimization would be used to find the best molecule in the chemical space, whereas active learning would be used to create accurate and robust models. The active learning approach would also be useful for creating an ML model which could be used as a cheap filter in the filter approach.
If the generative model represents the molecules in a latent space, such as in a VAE and normalizing flow, one could instead train a machine learning model to predict the given properties from the latent space. The problem can then be treated as an inverse design problem, where promising candidates are optimized in the latent space. Then the latent space representation can be transformed back into a molecule for further exploration. These methods allow for gradient-based techniques to be used to find the best molecule.
A different approach is to instead train your generative model on molecules that are already known to pass your requirements, such as synthesis cost and manufacturability. So instead of learning the distributions of all molecules, the generative model will instead learn the distribution of molecules that pass your requirements. The new generative model would then generate molecules that pass your requirements. However, this requires the data to be labeled, essentially converting the problem from an unsupervised task to a supervised one. To reduce the data requirements, one can start with a pre-trained generative model and then tune the model. The major advantage of this approach is that the molecules are more likely to pass your requirements, so fewer molecules have to be generated and tested.
Staying Ahead of the Curve
While there are several important factors to consider when utilizing these generative models for molecules, these technologies are becoming mature enough such that valuable and industrially viable materials informatics software solutions can now be built. Integrating generative methods into your workflows can help quickly identify promising candidates that meet all of your design requirements since the generative models for molecules can be thought of as giving you access to an infinite database of promising new molecules. Innovation leaders are investing in learning how to leverage these tools in their R&D teams to give them a competitive advantage, especially when pursuing new markets with high growth potential and room for major chemical innovation.
Watch Webinar-on-Demand: Materials Informatics for Product Development: Deliver Big with Small Data
Related Content
イベントレポート | DXからインテリジェンス・ドリブンへ ~
エンソート創立25周年を記念した特別版として開催された本年度のサミットは、R&D領域のリーダーや経営層が一堂に会し、150名以上にご参加いただきました。 「DXからインテリジェンス・ドリブンへ ~ 科学的R&Dイノベーションの次代」をテーマとし、AIが加速する時代において研究開発組織がいかに進化すべきかが多角的に考察。本記事では各セッションの要点をレポートいたします。
科学的R&Dの転換点 ── エージェンティックAIは何を変えたのか
最先端AIを開発する企業は、いま、次々と科学研究の領域へ本格的に参入しています。これまで解決が難しかった科学的課題に対し、AIを「単なる支援ツール」ではなく、研究開発プロセスそのものを前進させる協働パートナーとして活用する時代が始まっています。本記事では、AIが「個別タスクを支援する技術」から、「研究開発プロセス全体を横断的に支援し推進する協働者」へと進化し始めた背景を具体的に紐解きます。
【イベントレポート】エージェント型AIが変える素材開発の未来 〜 MIとの融合による『自律型R&D』の最前線 〜
マテリアルズ・インフォマティクス(MI)と最新の「エージェント型AI」の融合をテーマに、産学それぞれの第一線で活躍する専門家が登壇。労働人口の減少や研究開発の属人化といった課題を抱える日本の素材産業において、いかにAIを「パートナー」として使いこなし、自律的な研究体制を構築すべきか、その具体的な道筋が示されました。
コンカレント材料設計:AIで実現する次世代アプローチ
AIの高度最適化、生成AI、エージェント型AIの活用により、材料と製品を同時に設計・最適化するコンカレント材料設計についてご紹介します。開発スピードと自由度が飛躍的に向上させることで、性能向上や市場投入までの期間短縮、競争優位性の確立が可能となります。
「収益性の壁」を超える:AIの活用で機能性材料開発を戦略から再構築
スペシャルティケミカルおよび素材産業は、コモディティ化と価格競争の激化により、従来の差別化戦略では持続的成長が難しくなっています。こうした中、AIやマテリアルズインフォマティクス(MI)などの先端技術が、R&D戦略の再構築と成長再加速への有力な打ち手として注目されています。
研究開発組織の変革を成功させるためのパートナー選び
現在の競争が激しいR&D環境において、適切なテクノロジーパートナーを選ぶことは、組織にとって最も重要な意思決定の1つです。理想的なパートナーとは、単なるツールベンダーやシステムインテグレーターではなく、生産性を向上させ、イノベーションを加速し、競争力を引き出す解決策を提供する科学的な専門知識と戦略的な洞察を兼ね備えた「変革の同志」です。
「AIスーパー・モデル」が材料研究開発を革新する
近年、計算能力と人工知能の進化により、材料科学や化学の研究・製品開発に変革がもたらされています。エンソートは常に最先端のツールを探求しており、研究開発の新たなステージに引き上げる可能性を持つマテリアルズインフォマティクス(MI)分野での新技術を注視しています。
デジタルトランスフォーメーション vs. デジタルエンハンスメント: 研究開発における技術イニシアティブのフレームワーク
生成AIの登場により、研究開発の方法が革新され、前例のない速さで新しい科学的発見が生まれる時代が到来しました。研究開発におけるデジタル技術の導入は、競争力を向上させることが証明されており、企業が従来のシステムやプロセスに固執することはリスクとなります。デジタルトランスフォーメーションは、科学主導の企業にとってもはや避けられない取り組みです。
産業用の材料と化学研究開発におけるLLMの活用
大規模言語モデル(LLM)は、すべての材料および化学研究開発組織の技術ソリューションセットに含むべき魅力的なツールであり、変革をもたらす可能性を秘めています。